2.1 QPanda¶
一种功能齐全,运行高效的量子软件开发工具包
QPanda 2是由本源量子开发的开源量子计算框架,它可以用于构建、运行和优化量子算法。QPanda 2作为本源量子计算系列软件的基础库,为QRunes、Qurator、量子计算服务提供核心部件。
编译环境
QPanda 2是以C++为宿主语言,其对系统的环境要求如表附2.1.1:
表附2.1.1 环境要求
software |
version |
CMake |
>= 3.1 |
GCC |
>= 5.0 |
Python |
>= 3.7.0 |
下载QPanda 2
如果在您的系统上已经安装了git, 你可以直接输入以下命令来获取QPanda2:
$ git clone https://github.com/OriginQ/QPanda 2.git
对于一些为安装git的伙伴来说,也可以直接通过浏览器去下载QPanda 2, 具体的操作步骤如下:
1.在浏览器中输入 https://github.com/OriginQ/QPanda 2 ,进入网页会看到:

图附2.1.1 Github界面
2.点击 Clone or download 看到界面:

图附2.1.2 Github界面
3.然后点击 Download ZIP, 就会完成QPanda2的下载。

图附2.1.3 下载
编译
我们支持在Windows、Linux、MacOS下构建QPanda 2。用户可以通过CMake的方式来构建QPanda 2。
Windows
在Windows构建QPanda 2。用户首先需要保证在当前主机下安装了CMake环境和C++编译环境,用户可以通过Visual Studio和MinGW方式编译QPanda 2。
1. 使用Visual Studio
这里以Visual Studio 2017为例,使用Visual Studio 2017 编译QPanda 2,只需要安装Visual Studio 2017,并需要在组件中安装CMake组件。安装完成之后,用Visual Studio 2017打开QPanda 2文件夹,即可使用CMake编译QPanda 2。

图附2.1.4 使用CMake编译QPanda2
2. 使用MinGW
使用MinGW编译QPanda 2,需要自行搭建CMake和MinGW环境,用户可自行在网上查询环境搭建教程。(注意: MinGW需要安装64位版本)
CMake+MinGW的编译命令如下:
1. 在QPanda 2根目录下创建build文件夹
2. 进入build文件夹,打开cmd
3. 由于MinGW对CUDA的支持存在一些问题,所以在编译时需要禁掉CUDA,输入以下命令:
1.cmake -G"MinGW Makefiles" -DFIND_CUDA=OFF -DCMAKE_INSTALL_PREFIX=C:/QPanda2 ..
2.mingw32-make
Linux 和MacOS
在Linux和MacOS下编译QPanda 2,命令是一样的。
编译步骤如下:
1. 进入QPanda 2根目录
2. 输入以下命令:
1.mkdir -p build
2.cd build
3.cmake ..
4.make
如果有需求,用户通过命令修改QPanda 2的安装路径,配置方法如下所示:
1.mkdir -p build
2.cd build
3.cmake -DCMAKE_INSTALL_PREFIX=/usr/local ..
4.make
安装
QPanda 2编译完成后,会以库的形式存在。为了方便调用,大家可以把QPanda 2库安装到指定位置,安装的方式如下所示。
Windows
1. 使用Visual Studio
同样以Visual Studio 2017为例,在QPanda 2编译完成后,用户可以安装,Visual Studio 2017的安装方式很简单,只需要在Cmake菜单中选择安装即可。
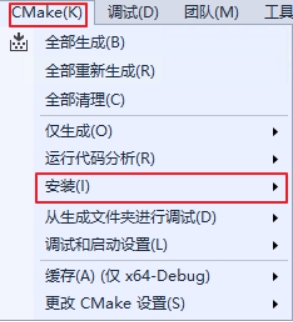
图附2.1.5 在Cmake菜单中选择“安装”
QPanda 2会安装在用户在CMakeSettings.json中配置的安装目录下。安装成功后会在用户配置的的目录下生成install文件夹,里面安装生成include和lib文件。如果有需求,用户可以在Visual Studio的CMakeSettings.json配置文件修改的安装路径。生成CMakeSettings.json的方法如下图所示:

图附2.1.6 生成CMakeSettings.json的方法
修改QPanda 2的安装路径如下图所示:

图附2.1.7 修改QPanda 2的安装路径
参数修改完成后,cmake选项下执行安装,QPanda 2的lib库文件和include头文件会安装到用户指定的安装位置。(注意:需先进行编译成功后才能进行安装)
2. 使用MinGW
在QPanda 2编译完成后,用户可以安装QPanda 2,安装命令如下:
1.mingw32-make install
Linux 和MacOS
在Linux和MacOS下安装命令QPanda 2,命令是一样的,安装命令如下:
1.sudo make install
使用
不同的平台和不同的IDE在构建C++项目是的方法是不一样的,调用库的方式也不尽相同,大家可以选择用自己的方式调用QPanda 2库, 下面我们以cmake构建项目为例,演示调用QPanda 2库进行量子编程。
Visual Studio调用QPanda 2库
Visual Studio下调用QPanda 2库的CMakeList的写法为
1.cmake_minimum_required(VERSION 3.1)
2.project(testQPanda)
3.SET(CMAKE_INSTALL_PREFIX "C:/QPanda2") # QPanda2安装的路径
4.SET(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "${CMAKE_INSTALL_PREFIX}/lib/cmake")
5.
6.set(CMAKE_CXX_STANDARD 14)
7.set(CMAKE_CXX_STANDARD_REQUIRED ON)
8.if (NOT USE_MSVC_RUNTIME_LIBRARY_DLL)
9. foreach (flag
10. CMAKE_C_FLAGS
11. CMAKE_C_FLAGS_DEBUG
12. CMAKE_C_FLAGS_RELEASE
13. CMAKE_C_FLAGS_MINSIZEREL
14. CMAKE_C_FLAGS_RELWITHDEBINFO
15. CMAKE_CXX_FLAGS
16. CMAKE_CXX_FLAGS_DEBUG
17. CMAKE_CXX_FLAGS_RELEASE
18. CMAKE_CXX_FLAGS_MINSIZEREL
19. CMAKE_CXX_FLAGS_RELWITHDEBINFO)
20.
21. if (${flag} MATCHES "/MD")
22. string(REGEX REPLACE "/MD" "/MT" ${flag} "${${flag}}")
23. endif()
24. if (${flag} MATCHES "/MDd")
25. string(REGEX REPLACE "/MDd" "/MTd" ${flag} "${${flag}}")
26. endif()
27. if (${flag} MATCHES "/W3")
28. string(REGEX REPLACE "/W3" "/W0" ${flag} "${${flag}}")
29. endif()
30. endforeach()
31.endif()
32.
33.set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
34.set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
35.
36.find_package(OpenMP)
37.if(OPENMP_FOUND)
38. option(USE_OPENMP "find OpenMP" ON)
39. message("OPENMP FOUND")
40. set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
41. set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
42. set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
43.else(OPENMP_FOUND)
44. option(USE_OPENMP "not find OpenMP" OFF)
45.endif(OPENMP_FOUND)
46.
47.find_package(QPANDA REQUIRED)
48.if (QPANDA_FOUND)
49. include_directories(${QPANDA_INCLUDE_DIR})
50.endif (QPANDA_FOUND)
51.
52.add_executable(${PROJECT_NAME} test.cpp)
53.target_link_libraries(${PROJECT_NAME} ${QPANDA_LIBRARIES})
MinGW调用QPanda 2库
MinGW调用QPanda 2库的CMakeList的写法为
1.cmake_minimum_required(VERSION 3.1)
2.project(testQPanda)
3.SET(CMAKE_INSTALL_PREFIX "C:/QPanda2") # QPanda2安装的路径
4.SET(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "${CMAKE_INSTALL_PREFIX}/lib/cmake")
5.
6.
7.add_definitions("-w -DGTEST_USE_OWN_TR1_TUPLE=1")
8.set(CMAKE_BUILD_TYPE "Release")
9.set(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -g -ggdb")
10.set(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3")
11.add_compile_options(-fpermissive)
12.
13.set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
14.set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
15.
16.find_package(OpenMP)
17.if(OPENMP_FOUND)
18. option(USE_OPENMP "find OpenMP" ON)
19. message("OPENMP FOUND")
20. set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
21. set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
22. set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
23.else(OPENMP_FOUND)
24. option(USE_OPENMP "not find OpenMP" OFF)
25.endif(OPENMP_FOUND)
26.
27.find_package(QPANDA REQUIRED)
28.if (QPANDA_FOUND)
29. include_directories(${QPANDA_INCLUDE_DIR})
30.endif (QPANDA_FOUND)
31.
32.add_executable(${PROJECT_NAME} test.cpp)
33.target_link_libraries(${PROJECT_NAME} ${QPANDA_LIBRARIES})
linux、MacOS下使用QPanda2
linux、MacOS使用QPanda2的方式是相同的,其CmakeList.txt的写法为:
1.cmake_minimum_required(VERSION 3.1)
2.project(testQPanda)
3.SET(CMAKE_INSTALL_PREFIX "/usr/local") # QPanda2安装的路径
4.SET(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "${CMAKE_INSTALL_PREFIX}/lib/cmake")
5.
6.
7.add_definitions("-w -DGTEST_USE_OWN_TR1_TUPLE=1")
8.set(CMAKE_BUILD_TYPE "Release")
9.set(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -g -ggdb")
10.set(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3")
11.add_compile_options(-fpermissive)
12.
13.set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
14.set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
15.
16.find_package(OpenMP)
17.if(OPENMP_FOUND)
18. option(USE_OPENMP "find OpenMP" ON)
19. message("OPENMP FOUND")
20. set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
21. set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
22. set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
23.else(OPENMP_FOUND)
24. option(USE_OPENMP "not find OpenMP" OFF)
25.endif(OPENMP_FOUND)
26.
27.find_package(QPANDA REQUIRED)
28.if (QPANDA_FOUND)
29. include_directories(${QPANDA_INCLUDE_DIR})
30.endif (QPANDA_FOUND)
31.
32.add_executable(${PROJECT_NAME} test.cpp)
33.target_link_libraries(${PROJECT_NAME} ${QPANDA_LIBRARIES})
Note
test.cpp 为使用QPanda2的一个示例。有兴趣的可以试着将其合并在一起形成一个跨平台的CMakeList.txt。
通过一个示例介绍QPanda 2的使用,下面的例子可以在量子计算机中构建量子纠缠态 \((|00\rangle +|11\rangle)\) ,对其进行测量,重复制备1000次。 预期的结果是约有50%的概率使测量结果分别在00或11上。
1.#include "QPanda.h"
2.using namespace QPanda;
3.int main()
4.{
5. auto qvm = CPUQVM();
6. auto prog = QProg();
7. auto q = qvm.qAllocMany(2);
8. auto c = qvm.cAllocMany(2);
9. prog << H(q[0])
10. << CNOT(q[0],q[1])
11. << MeasureAll(q, c);
12. auto results = qvm.runWithConfiguration(prog, c, 1000);
13. for (auto result : results){
14. std::cout << result.first << " : " << result.second << std::endl;
15. }
16. return 0;
17.}
编译方式与编译QPanda库的方式基本类似,在这里就不多做赘述。
编译之后的可执行文件会生成在build下的bin文件夹中,进入到bin目录下就可以执行自己编写的量子程序了。
计算结果如下所示:
1.00 : 493
2.11 : 507
2.2 pyQPanda¶
系统配置和安装
我们通过pybind11工具,以一种直接和简明的方式,对QPanda2中的函数、类进行封装,并且提供了几乎完美的映射功能。 封装部分的代码在QPanda2编译时会生成为动态库,从而可以作为Python的包引入。
系统配置
pyqpanda是以C++为宿主语言,其对系统的环境要求如表附2.2.1:
表附2.2.1 环境要求
software |
version |
GCC |
>= 5.4.0 |
Python |
>= 3.7.0 |
下载pyqpanda
如果你已经安装好了Python环境和pip工具, 在终端或者控制台输入下面命令:
pip install pyqpanda
Note
在linux下若遇到权限问题需要加 sudo
2.3 VQNet¶
2.3.1 VQNet python包安装¶
我们提供了Linux,Windows,MacOS上的python预编译包供安装,需要python==3.8。还需要numpy>=1.18.5,pyqpanda>=3.7.8。
pip install pyvqnet
VQNet 测试安装成功
import pyvqnet
from pyvqnet.tensor import *
a = arange(1,25).reshape([2, 3, 4])
print(a)
2.3.2 VQNet 的一个简单例子¶
这里使用VQNet的经典神经网络模块以及量子模块完成一个机器学习模型的整体流程的例子介绍。该例子参考 [Data re-uploading for a universal quantum classifier](https://arxiv.org/abs/1907.02085) 。 量子机器学习中的量子计算模块一般有如下几个部分:
(1)编码线路(Encoder),用于将经典数据编码到量子数据; (2)可变参数的量子线路(Ansatz),用于训练带参量子门中的参数; (3)测量模块(Measurement),用于检测测量值(也就是某个量子比特的量子态在某些轴上的投影)。
量子计算模块与经典神经网络的运算模块一样是可微分的,是量子经典神经网络混合模型的理论基础。 VQNet支持将量子计算模块与经典计算模块(例如:卷积,池化,全连接层,激活函数等)一起构成混合机器学习模型,提供多种优化算法优化参数。

在量子计算模块,VQNet支持使用本源量子高效的量子软件计算包 [pyQPanda](https://pyqpanda-toturial.readthedocs.io/zh/latest/) 进行量子模块构建。 使用pyQPanda提供的各种常用 [量子逻辑门函数接口](https://pyqpanda-toturial.readthedocs.io/zh/latest/QGate.html) , [量子线路接口](https://pyqpanda-toturial.readthedocs.io/zh/latest/QCircuit.html) , [量子虚拟机函数接口](https://pyqpanda-toturial.readthedocs.io/zh/latest/QuantumMachine.html) , [测量函数接口](https://pyqpanda-toturial.readthedocs.io/zh/latest/Measure.html),用户可以快速构建量子计算模块。
接下来的例子我们使用pyQPanda构建了一个量子计算模块。通过VQNet,该量子计算模块可以直接嵌入到混合机器学习模型中进行量子线路参数训练。 本例使用1个量子比特,使用了多个带参数的旋转门 RZ,RY,RZ 对输入x进行编码,并使用 prob_run_dict() 函数观测量子比特的概率测量结果作为输出。
def qdrl_circuit(input,weights,qlist,clist,machine):
x1 = input.squeeze()
param1 = weights.squeeze()
#使用pyqpanda接口构建量子线路实例
circult = pq.QCircuit()
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[0]
circult.insert(pq.RZ(qlist[0], x1[0]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位x1[1]
circult.insert(pq.RY(qlist[0], x1[1]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[2]
circult.insert(pq.RZ(qlist[0], x1[2]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[0]
circult.insert(pq.RZ(qlist[0], param1[0]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位param1[1]
circult.insert(pq.RY(qlist[0], param1[1]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[2]
circult.insert(pq.RZ(qlist[0], param1[2]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[0]
circult.insert(pq.RZ(qlist[0], x1[0]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位x1[1]
circult.insert(pq.RY(qlist[0], x1[1]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[2]
circult.insert(pq.RZ(qlist[0], x1[2]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[3]
circult.insert(pq.RZ(qlist[0], param1[3]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位param1[4]
circult.insert(pq.RY(qlist[0], param1[4]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[5]
circult.insert(pq.RZ(qlist[0], param1[5]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[0]
circult.insert(pq.RZ(qlist[0], x1[0]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位x1[1]
circult.insert(pq.RY(qlist[0], x1[1]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位x1[2]
circult.insert(pq.RZ(qlist[0], x1[2]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[6]
circult.insert(pq.RZ(qlist[0], param1[6]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RY门,参数位param1[7]
circult.insert(pq.RY(qlist[0], param1[7]))
#使用pyqpanda接口在第一个量子比特上插入逻辑门RZ门,参数位param1[8]
circult.insert(pq.RZ(qlist[0], param1[8]))
#构建量子程序
prog = pq.QProg()
prog.insert(circult)
#获取概率测量值
prob = machine.prob_run_dict(prog, qlist, -1)
prob = list(prob.values())
return prob
本例子中机器学习的任务是对随机生成的数据根据进行二分类,其中下图是该数据样例,零为圆点,半径为1以内红色的二维点为一类,蓝色的点为另一类。

图附2.3.1 数据样例
训练测试代码流程:
#导入必须的库和函数
from pyvqnet.qnn.qdrl.vqnet_model import qdrl_circuit
from pyvqnet.qnn.quantumlayer import QuantumLayer
from pyvqnet.optim import adam
from pyvqnet.nn.loss import CategoricalCrossEntropy
from pyvqnet.tensor import QTensor
import numpy as np
from pyvqnet.nn.module import Module
定义模型Model,其中 __init__ 函数定义内部各个神经网络模块以及量子模块,forward 函数定义前传函数。QuantumLayer 为封装量子计算的抽象类。 您只需将刚才定义的量子计算函数 qdrl_circuit,待训练参数个数 param_num ,运行后端配置 “cpu” , 量子比特数 qbit_num 输入参数,该类就在 VQNet 中自动计算参数梯度。
#待训练参数个数
param_num = 9
#量子计算模块量子比特数
qbit_num = 1
#定义一个继承于Module的机器学习模型类
class Model(Module):
def __init__(self):
super(Model, self).__init__()
#使用QuantumLayer类,可以把带训练参数的量子线路纳入VQNet的自动微分的训练流程中
self.pqc = QuantumLayer(qdrl_circuit,param_num,"cpu",qbit_num)
#定义模型前向函数
def forward(self, x):
x = self.pqc(x)
return x
定义一些训练模型需要的函数
# 随机产生待训练数据的函数
def circle(samples:int, rads = np.sqrt(2/np.pi)) :
data_x, data_y = [], []
for i in range(samples):
x = 2*np.random.rand(2) - 1
y = [0,1]
if np.linalg.norm(x) < rads:
y = [1,0]
data_x.append(x)
data_y.append(y)
return np.array(data_x), np.array(data_y)
# 数据载入函数
def get_minibatch_data(x_data, label, batch_size):
for i in range(0,x_data.shape[0]-batch_size+1,batch_size):
idxs = slice(i, i + batch_size)
yield x_data[idxs], label[idxs]
#计算准确率的函数
def get_score(pred, label):
pred, label = np.array(pred.data), np.array(label.data)
pred = np.argmax(pred,axis=1)
score = np.argmax(label,1)
score = np.sum(pred == score)
return score
VQNet遵循机器学习一般的训练测试流程: 迭代进行载入数据,前传计算,损失函数计算,反向计算,更新参数的操作。
#实例化定义的模型
model = Model()
#定义一个优化器,这里用的是Adam
optimizer = adam.Adam(model.parameters(),lr =0.6)
#定义一个损失函数,这里用的交叉熵损失函数
Closs = CategoricalCrossEntropy()
训练模型部分的函数
def train():
# 随机产生待训练数据
x_train, y_train = circle(500)
x_train = np.hstack((x_train, np.zeros((x_train.shape[0], 1))))
# 定义每个批次训练的数据个数
batch_size = 32
# 最大训练迭代次数
epoch = 10
print("start training...........")
for i in range(epoch):
model.train()
accuracy = 0
count = 0
loss = 0
for data, label in get_minibatch_data(x_train, y_train,batch_size):
# 优化器中缓存梯度清零
optimizer.zero_grad()
# 模型前向计算
output = model(data)
# 损失函数计算
losss = Closs(label, output)
# 损失反向传播
losss.backward()
# 优化器参数更新
optimizer._step()
# 计算准确率等指标
accuracy += get_score(output,label)
loss += losss.item()
count += batch_size
print(f"epoch:{i}, train_accuracy:{accuracy/count}")
print(f"epoch:{i}, train_loss:{loss/count}\n")
验证模型部分的函数
def test():
batch_size = 1
model.eval()
print("start eval...................")
xtest, y_test = circle(500)
test_accuracy = 0
count = 0
x_test = np.hstack((xtest, np.zeros((xtest.shape[0], 1))))
predicted_test = []
for test_data, test_label in get_minibatch_data(x_test,y_test, batch_size):
test_data, test_label = QTensor(test_data),QTensor(test_label)
output = model(test_data)
test_accuracy += get_score(output, test_label)
count += batch_size
print(f"test_accuracy:{test_accuracy/count}")
训练测试结果图
start training...........
epoch:0, train_accuracy:0.6145833333333334
epoch:0, train_loss:0.020432369535168013
epoch:1, train_accuracy:0.6854166666666667
epoch:1, train_loss:0.01872217481335004
epoch:2, train_accuracy:0.8104166666666667
epoch:2, train_loss:0.016634768371780715
epoch:3, train_accuracy:0.7479166666666667
epoch:3, train_loss:0.016975031544764835
epoch:4, train_accuracy:0.7875
epoch:4, train_loss:0.016502128106852372
epoch:5, train_accuracy:0.8083333333333333
epoch:5, train_loss:0.0163204787299037
epoch:6, train_accuracy:0.8083333333333333
epoch:6, train_loss:0.01634311651190122
epoch:7, train_loss:0.016330583145221074
epoch:8, train_accuracy:0.8125
epoch:8, train_loss:0.01629052646458149
epoch:9, train_accuracy:0.8083333333333333
epoch:9, train_loss:0.016270687493185203
start eval...................
test_accuracy:0.826
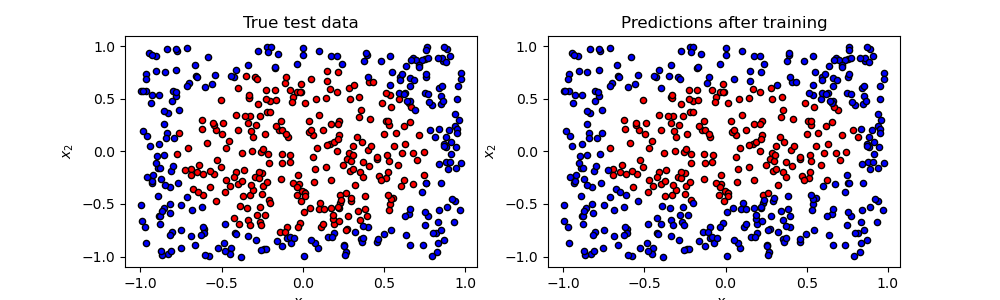
图附2.3.2 训练测试结果图
2.4 Qurator¶
一种基于VS Code的量子程序开发工具。
qurator-vscode 是本源量子推出的一款可以开发量子程序的 VS Code 插件。其支持 QRunes2 语言量子程序开发,并支持 Python 和 C++ 语言作为经典宿主语言。
在 qurator-vscode 中,量子程序的开发主要分为编写和运行两个部分。
·编写程序:插件支持模块化编程,在不同的模块实现不同的功能,其中量子程序的编写主要在 qcodes 模块中;
·程序运行:即是收集结果的过程,插件支持图表化数据展示,将运行结果更加清晰的展现在您的面前。
2.4.1 设计思想¶
考虑到目前量子程序的开发离不开经典宿主语言的辅助,qurator-vscode 插件设计时考虑到一下几点:
(1)模块编程:
qurator-vscode 插件支持模块编程,将整体程序分为三个模块:settings、qcodes 和 script 模块。在不同的模块完成不同的功能。 在 settings 模块中,您可以进行宿主语言类型、编译还是运行等设置;在 qcodes 模块中, 您可以编写 QRunes2 语言程序; 在 script 模块中,您可以编写相应的宿主语言程序。
(2)切换简单:
qurator-vscode 插件目前支持两种宿主语言,分别为 Python 和 C++。您可以在两种宿主语言之间自由的切换,您只需要在 settings 模块中设置 language 的 类型,就可以在 script 模块中编写对应宿主语言的代码。插件会自动识别您所选择的宿主语言,并在 script 模块中提供相应的辅助功能。
(3)图形展示:
qurator-vscode 插件提供图形化的结果展示,程序运行后会展示 json 格式的运行结果,您可以点击运行结果,会生成相应的柱状图,方便您对运行结果的分析。
2.4.2 准备工作¶
使用 qurator-vscode 插件之前需要做一些准备工作,以确保量子程序能够正确的运行。
需要依赖的运行环境有:
·Python (版本 3.6.4 - 3.6.8)
·Pip (版本 10.1 及以上)
·Microsoft Visual C++ Redistributable (Windows)
·MinGw-w64 (Windows 64位版本)
其中,pip 负责下载宿主语言为 Python 时程序运行所依赖的包。Microsoft Visual C++ Redistributable 和 MinGw-w64 是宿主语言为 C++ 时程序运行所依赖的包。
(1)安装插件
首先需要您安装 [VS Code](https://code.visualstudio.com/) ,然后打开 VS Code 安装 qurator-vscode 插件: 使用 Ctrl + Shift + X 快捷键打开插件页面,或者您可以在最左侧栏找到 Extensions 点击进入,然后输入 qurator-vscode 来搜索插件,点击 Install 按钮进行插件的安装。

图附2.4.1 插件安装
(2)检测运行环境
插件安装好之后,您可以创建以 .qrunes 结尾的文件,此时插件会自动检测是否存在程序运行所依赖的环境。您也可以自己检测程序运行环境,使用 Ctrl + Shift + P 快捷键打开 VS Code 命令行, 输入 qurator-vscode 时您可以看到 qurator-vscode: Check Qurator VSCode Extension dependencies 选择项,点击此项就可以进行运行环境的检测。

图附2.4.2 运行环境检测
检测到运行时所需环境,会在右下角展示软件及版本号:
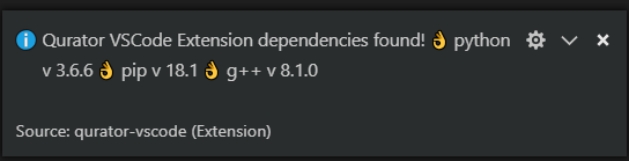
图附2.3.3 软件及版本号
2.4.3 快速入门¶
在做好准备工作之后,下面就可以编写属于您自己的量子程序了。
(1)项目文件夹中启动 VS Code
在命令提示符或终端上,创建一个名为 “test” 的空文件夹,切换到该文件夹,然后输入命令 code . 在该文件夹中打开 VS Code:
1.mkdir test
2.cd test
3.code .
或者,您可以点击运行 VS Code,然后点击 “File” > “Open File…” 打开项目文件夹。在文件夹中启动 VS Code,该文件夹将成为您的“工作区”。您可以在 .vscode/settings.json 文件中更改工作区的相关设置。
(2)创建一个 qrunes 文件
在文件资源管理器工具栏中,单击 “test” 文件夹上的 “New File” 按钮,并命名该文件为 qurator_test.qrunes。
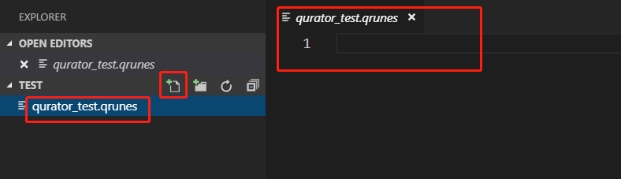
图附2.4.4 创建 qrunes 文件
(3)编写量子程序
qrunes 文件创建完成之后,便可以编写量子程序了。整个量子程序分为三个部分:settings、qcodes 和 script 三个模块。
其中,settings 模块中可以设置宿主语言,编译还是运行;qcodes 模块中可以编写 QRunes2 量子语言代码; script 模块中可以编写宿主语言代码,目前支持 Python 和 C++ 两种宿主语言。

图附2.4.5 编写量子程序
(4)编译运行
点击右上方 Run this QRunes 运行程序,或者使用命令提示符 qurator-vscode: Run this QRunes 来运行程序(快捷键 F5):


图附2.4.6 编译运行
上述示例程序的运行结果如图附2.3.7:
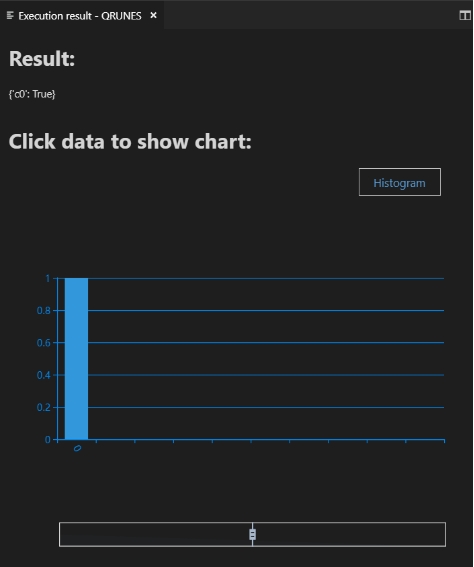
图附2.4.7 运行结果
2.4.4 功能介绍¶
相信在快速入门步骤之后,您已大体了解插件的整体功能,下面将介绍您在编辑量子程序过程中插件提供的辅助功能:
(1)自动补全
对于 QRunes2 语言内设的关键字可以智能提示,根据输入的字符列为您提供当前上下文中适用的最相关符号列表并提示其功能, 以便您可以更快地选择。
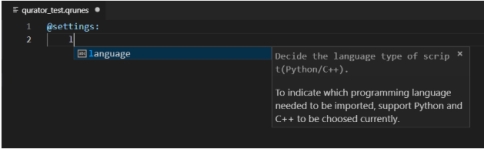
图附2.4.8 自动补全
(2)验证提示
对于输入进行验证并提示。每当插件检测到您编写的代码发生语法错误时,编辑器中会显示红色波浪线, 鼠标放上去可看到一系列错误信息,您可以准确定位错误发生的位置。
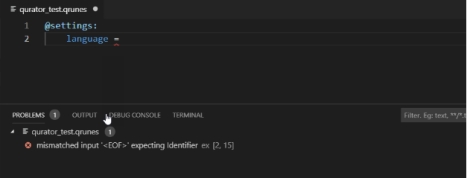
图附2.4.9 验证提示
(3)高亮展示
不同的模块有不同的颜色划分,您可以清晰地编写每一个模块的代码,一目了然,快速开发。

图附2.4.10 高亮展示
(4)悬浮提示
QRunes2 语言中的方法、变量都有详细的解释及用法。每当您编写 QRunes2 语言内设关键字时, 将鼠标放在该关键字上,编辑器将会显示该关键字的功能信息。
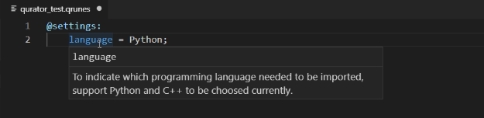
图附2.4.11 悬浮提示
(5)智能片段
智能片段功能是指用户输入简短的触发指令而生成完整的代码片段,在本插件中内置了自定义代码片段, 可帮助您整理一些重复性代码,提高开发效率。
图附2.4.12 智能片段
(6)语言切换
目前 QRunes2 语言可以支持 Python 及 C++ 宿主语言,您可以在 settings 模块的 language 关键字来设置 所需支持的语言类型,就可以在script模块编写相应语言的代码。
图附2.4.13 语言切换
(7)编译运行
运行 QRunes2 语言代码,编译器会根据设定的语言去编译该代码,从而实现不同的语言编写生成相同的结构。
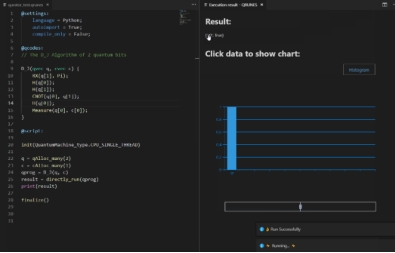
图附2.4.14 编译运行